Alibaba launched "AI Dianxiaomi", becoming the first customer service Agent in the e-commerce field that combines pre-sales consultation and after-sales service. The product is built based on the Tongyi Qianwen large model and leverages Taobao's massive transaction data for fine-tuning. With upgraded multimodal capabilities, it has evolved from an automated response tool into an intelligent customer service system capable of proactively understanding user needs.
Apple introduces two ML studies: SQUIRE enhances AI-generated UI control and fine-tuning with GPT-4o and slot query representation, while another improves image safety review to address current tech challenges.....
Rakuten AI 3.0, touted as Japan's largest AI model, faces criticism for removing original open-source licenses. Based on DeepSeek-V3, its compliance issues highlight industry-standard fine-tuning practices.....
Unsloth AI releases an open-source no-code visual tool called Unsloth Studio, aiming to simplify the fine-tuning process of large language models and lower the development threshold. The tool achieves double the training speed and saves 70% of VRAM usage through a customized backpropagation kernel, without requiring complex environment configuration or high hardware costs.
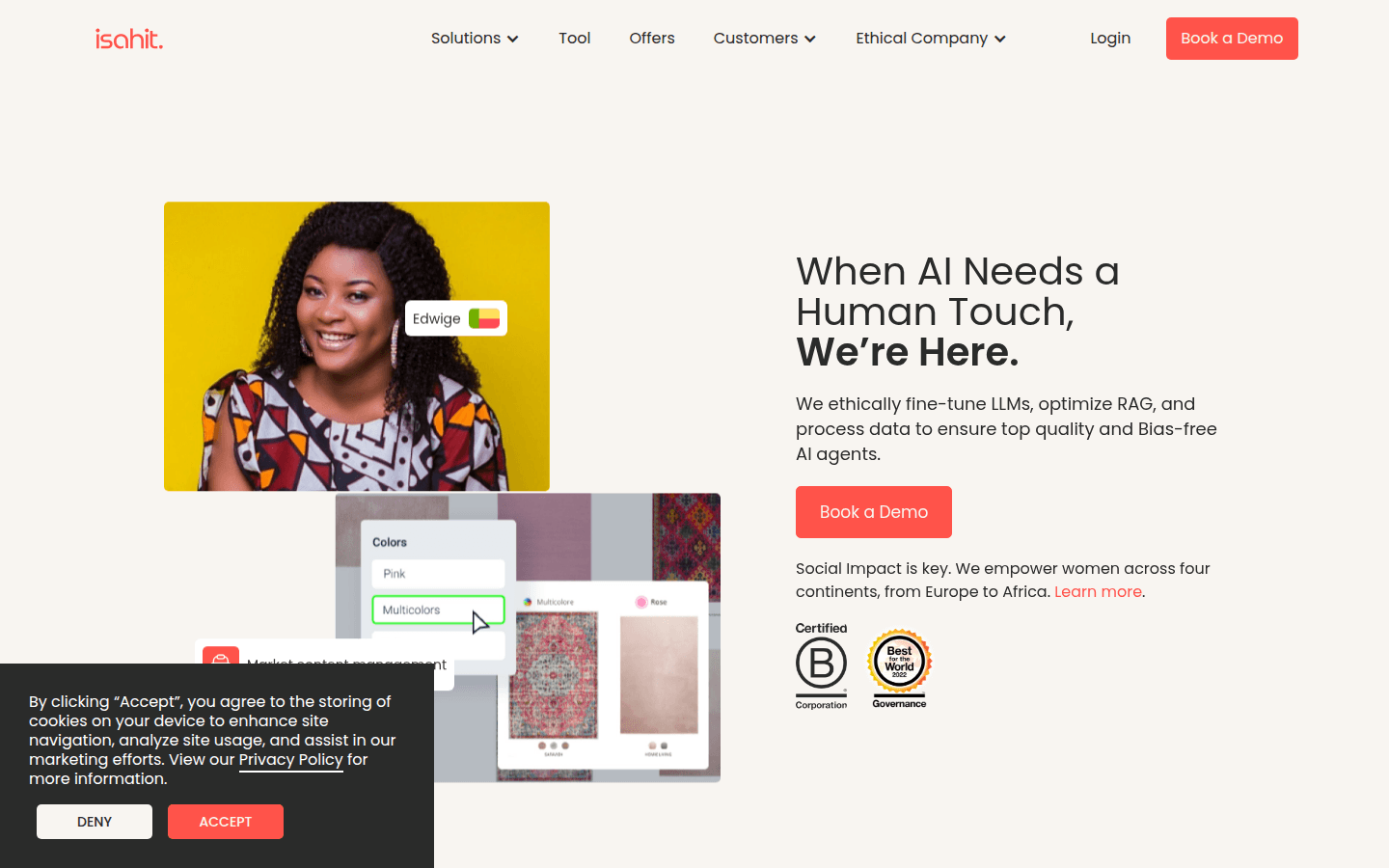
Isahit is a platform for managing staff, focusing on LLM fine-tuning and data processing to ensure the high quality and unbiased nature of AI agents.
An open-source platform for AI model fine-tuning and monetization, empowering AI startups, machine learning engineers, and researchers.
A platform for fine-tuning AI intelligent agents.
AI model fine-tuning, personalized customization.
Google
$0.7
Input tokens/M
$2.8
Output tokens/M
1k
Context Length
Anthropic
$7
$35
200
$2.1
$17.5
$21
$105
Alibaba
$3.9
$15.2
64
-
Bytedance
$0.8
$2
128
Deepseek
$4
$12
Tencent
$1
32
Openai
$1.75
$14
400
$525
Huawei
Chatglm
Iflytek
prithivMLmods
CodeV is a 7-billion-parameter vision-language model fine-tuned based on Qwen2.5-VL-7B-Instruct. Through two-stage training of supervised fine-tuning (SFT) and reinforcement learning (RL) based on tool-aware policy optimization (TAPO), it aims to achieve reliable and interpretable visual reasoning. It represents visual tools as executable Python code and ensures the consistency between tool usage and question evidence through a reward mechanism, solving the problem of irrelevant tool invocation under high accuracy.
mlx-community
This model is an MLX format conversion version of the Ministral-3-3B-Instruct-2512 instruction fine-tuning model released by Mistral AI. It is a large language model with a parameter scale of 3B, specifically optimized for following instructions and dialogue tasks, and supports multiple languages. The MLX format enables it to run efficiently on Apple Silicon devices.
Arko007
Zenyx_114M-Tiny-Edu-Instruct is an experimental small instruction fine-tuned language model with approximately 114 million parameters. It is built on the TinyEdu-50M base model, pre-trained on the FineWeb-Edu dataset, and fine-tuned on a mixed dataset of OpenHermes-2.5 and CodeFeedback-Filtered. This model aims to explore the limits of instruction fine-tuning under a minimal architecture and verify that the loss converges to approximately 1.04.
Olmo-3-7B-Instruct-AIO-GGUF is a GGUF quantized version based on the Olmo-3-7B-Instruct model developed by the Allen Institute for AI. This is an autoregressive language model with 7 billion parameters, trained on datasets such as Tulu 2 and UltraFeedback through supervised fine-tuning and direct preference optimization, and performs excellently in question-answering and instruction following.
allenai
Olmo 3 is a series of language models developed by the Allen Institute for AI, including two scales of 7B and 32B, with two variants: instructional and reflective. This model performs excellently in long-chain thinking and can effectively improve the performance of reasoning tasks such as mathematics and coding. It adopts a multi-stage training method, including supervised fine-tuning, direct preference optimization, and reinforcement learning with verifiable rewards.
Olmo-3-7B-Think-DPO is a 7B parameter language model developed by the Allen Institute for AI. It has the ability of long-chain thinking and performs excellently in reasoning tasks such as mathematics and coding. This model has undergone multi-stage training including supervised fine-tuning, direct preference optimization, and reinforcement learning based on verifiable rewards, and is designed specifically for research and educational purposes.
SadraCoding
SDXL-Deepfake-Detector is a tool for accurately detecting AI-generated faces. It focuses on maintaining the authenticity of the digital world and provides a privacy-protected and open-source solution to combat visual misinformation. This model achieves lightweight and highly accurate detection through fine-tuning a pre-trained model.
ethicalabs
xLSTM-7b-Instruct is an experimental fine-tuned version based on NX-AI/xLSTM-7b, specifically optimized for instruction-following tasks. This model adds support for chat templates and uses TRL for supervised fine-tuning training, aiming to provide a better conversational interaction experience.
Tesslate
WEBGEN DEVSTRAL IMAGES is an AI model focused on web page generation. It can generate single-page web pages using HTML, CSS, JS, and Tailwind technologies. This project is trained based on custom templates and uses the supervised fine-tuning method, training with a dataset generated by GPT-OSS-120B.
EpistemeAI
This model is based on GPT-OSS-20B and fine-tuned using the Unsloth reinforcement learning framework. The aim is to optimize inference efficiency and reduce vulnerabilities that occur during reinforcement learning from human feedback (RLHF) training. The fine-tuning process focuses on the robustness and efficiency of alignment, ensuring that the model maintains inference depth without incurring excessive computational overhead.
trinty2535425
This is an image-to-video LoRA model trained based on the Qwen/Qwen-Image base model. It uses the LoRA (Low-Rank Adaptation) technology to achieve efficient fine-tuning and can be used for related tasks such as AI image generation.
facebook
DINOv3 is a series of general visual foundation models developed by Meta AI. Without fine-tuning, it can outperform specialized state-of-the-art models in a wide range of visual tasks. This model uses self-supervised learning to generate high-quality dense features and performs excellently in various tasks such as image classification, segmentation, and depth estimation.
DINOv3 is a versatile visual foundation model developed by Meta AI. It can outperform specialized models in a wide range of visual tasks without fine-tuning. This model can generate high-quality dense features and performs excellently in various visual tasks, significantly surpassing previous self-supervised and weakly supervised foundation models.
DINOv3 is a series of general visual foundation models developed by Meta AI. It can outperform specialized advanced models in various visual tasks without fine-tuning. The model adopts the Vision Transformer architecture and is pre-trained on 1.689 billion web images. It can generate high-quality dense features and performs excellently in tasks such as image classification, segmentation, and retrieval.
danielkty22
TARS-SFT-7B is a security reasoning model based on supervised fine-tuning. It serves as the basic model for reinforcement learning training and is specifically designed to enhance the security of AI systems. This model starts training from Qwen2.5-7B-Instruct and uses the reasoning process as an adaptive defense mechanism to improve the security performance of the model.
OLMo 2 1B is a post-training variant of the allenai/OLMo-2-0425-1B-RLVR1 model, undergoing supervised fine-tuning, DPO training, and RLVR training, aiming to achieve state-of-the-art performance across multiple tasks.
ritvik77
A medical diagnosis AI model optimized through LoRA fine-tuning and 4-bit quantization technology based on the Mistral-7B language model, focusing on symptom analysis and disease diagnosis assistance.
us4
Fin-LLaMA 3.1 8B is a large language model fine-tuned specifically for financial news data based on the LLaMA 3.1 architecture. This model uses the Unsloth library for efficient fine-tuning, adopts LoRA adapter technology, and provides multiple quantized GGUF formats, aiming to generate coherent and relevant financial, economic, and business text responses.
cypienai
Cymist2-v0.1 is an advanced language model developed by Cypien AI team, specifically optimized for Turkish and English text generation tasks, supporting Retrieval-Augmented Generation (RAG) and Supervised Fine-Tuning (SFT).
KnutJaegersberg
The gpt2-chatbot is a dialogue model obtained through supervised fine-tuning (SFT) on the Deita dataset based on the GPT2-XL architecture, aiming to change a certain decision tendency. This model supports multi-turn dialogue and performs well in text generation tasks, but has limitations in mathematical reasoning.
The project involves documentation, sample code repositories, and community resources for the LangChain framework, including technical content such as Python programming, AI agent development, FastAPI integration, and LLM fine-tuning.
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)